Help
Tamil is largely a phonemic script. However, it is quite rich in allophones. For example,
unlike most other Indian languages which
phonemically differentiate voiced and un-voiced phones, they are considered allophones
in Tamil and hence not graphemically differentiated. Similarly, even with vowels several
allophonic variants can be seen.
This tool attempts
to analyze allphonic variants in a given Tamil input and produce a phonetically transcribed text.
It must be noted that this converter only corresponds to the standardized pronunciation of
Tamil in Tamil Nadu. Sri Lankan Tamil is quite different. For instance «ṟṟ» and «ṉṟ» are
pronounced differently in that dialect.
Limitations
The converter faces the following limitations. They may be overcome in the future.
The Transliteration of a word in ISO 15919 is enclosed by
«transliteration» and the approximate transcription in ISO 15919 by
/transcription/.
- The rules may not across a word boundary in case of a compound word.
- Lexical borrowings from other languages as usually nativized in pronunciation such as Sanskrit «matam» being pronounced as /madam/.
But like all languages some words tend to retain their original pronunciation (at least partially).
For instance, பயம் «payam» is realized as /bayam/.
The word-inital «p» is usually unvoiced but it has retained the voiced pronunciation of the original word /bhaya/ (but with the lost of
aspiration).
- Traditional grammars restrict «r» and «l»
not to appear in word-initial positions. Some circumvent this by introducing an epenthetic vowel usually an இ «i».
However,this is mostly orthographic. இராமன் «irāman»
is pronounced /rāman/, totally ignoring the initial epenthetic vowel.
(But few words such as இலங்கை «ilankai» have incorporated the epenthetic
vowel into actual pronunciation just because such lexical borrowings were made several centuries
earlier)
- Word-initial clusters and non-native clusters in other positions usually result in epenthesis.
Sometimes this is only orthographic as in the previous case.
The Sanskrit word /drōha/ is rendered in Tamil as துரோகம் «turōkam» but is realized as /drōgam/.
- There are several native tamil words that are deviant. For example,
பல்லி «balli» & குதி «kuti» are pronounced with word-initial voiced stops as
/balli/ & /gudi/ contrary to the general rules.
Font Display
The following fonts are dynamically loaded from the server to display IPA characters.
- Andika
- Charis SIL
- Dejavu Sans
- Dejavu Serif
- Doulos SIL
- Gentium Plus
- Lucida Sans Unicode
Hence, you should be able to view the IPA text without any problems.
If you do face problems in display, please install any of the listed fonts locally in your computer
Other Languages
Though this program mainly aims at IPA transcription, you may also view the transcribed Tamil
text in several Indian languages. They have been derived from my other tool
Aksharamukha.
Text Ouput
By default, the convert text is displayed in IPA and the original Tamil text is displayed as a tooltip. However
you may reverse the order or even use ruby texts to display the transcriptions.
API
The converter is also available has a REST API servive.
A POST or GET request must be sent to following URL : http://anunaadam.appspot.com/api with
the following parameters:
text: The Tamil text that needs to be transcribed
method: 1 for Narrow and 2 for broad
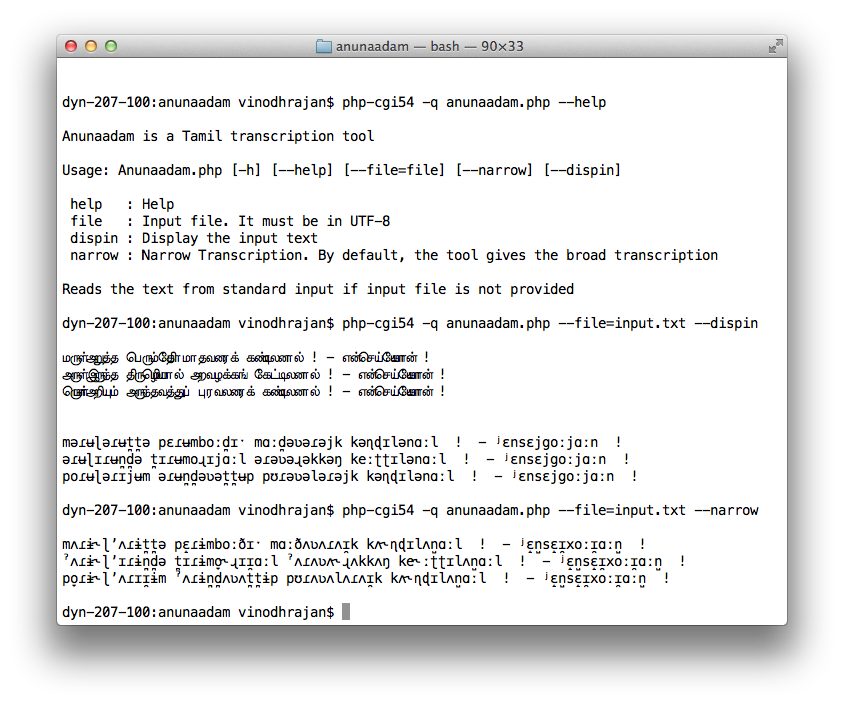
Terminal
You can also invoke this tool from the Terminal. Download the source code from Github. It has to be then invoked using the PHP CLI.
In OS X Mountain Lion, the in-built PHP doesn't seem to handle UTF-8 properly. You can install PHP 5.4 using Homebrew and then use it as CLI.